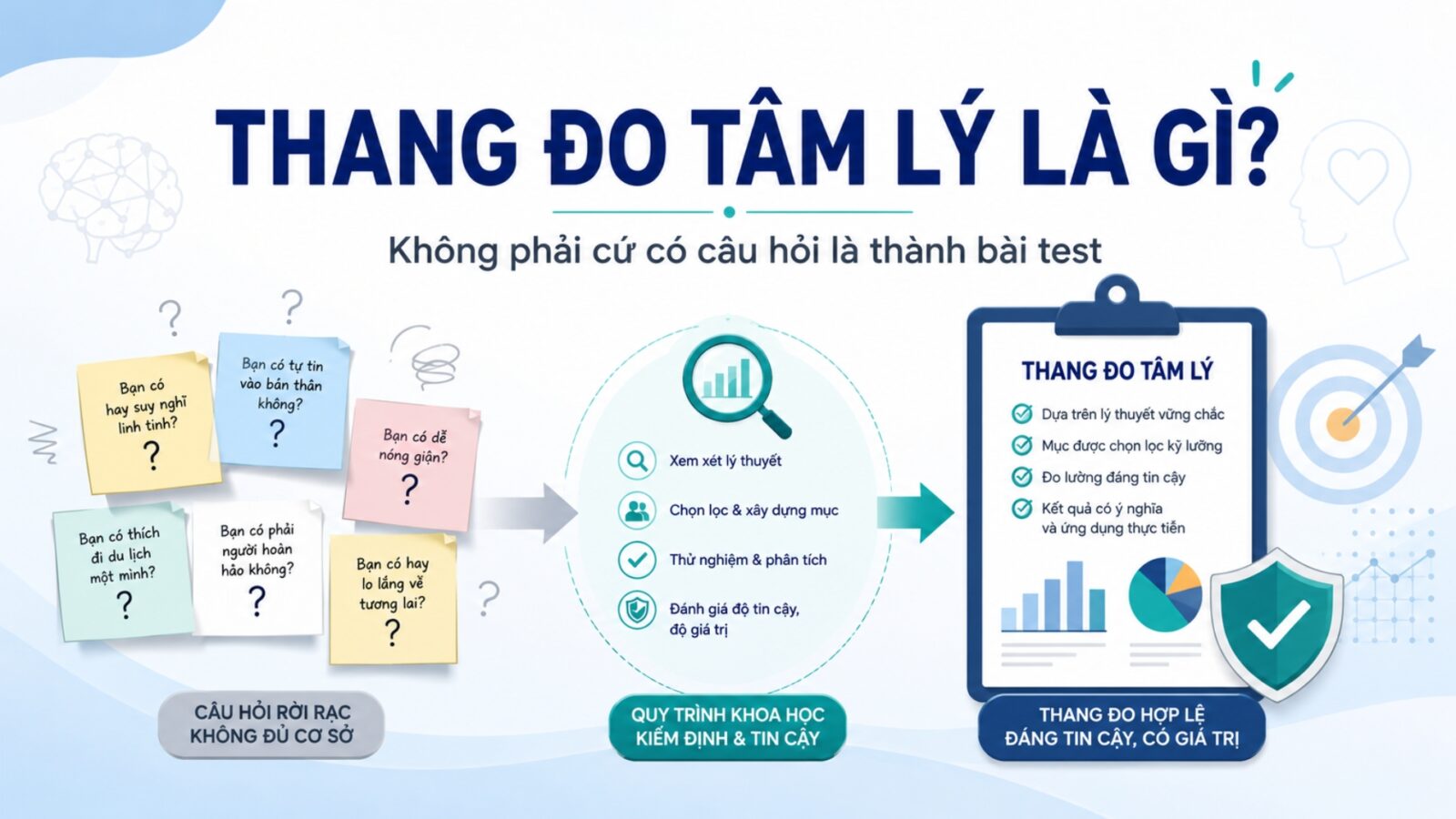
Một thang đo tâm lý không chỉ là một tờ giấy có câu hỏi. Nó là một công cụ được xây trên một ý tưởng lý thuyết rõ ràng về biến tiềm ẩn như lo âu, trầm cảm, tự trọng, kiệt sức hay thái độ. Vì biến này không nhìn thấy trực tiếp, người nghiên cứu phải dùng nhiều mục hỏi để “bắt tín hiệu” của nó, rồi kiểm tra xem các mục đó có thật sự cùng đo một thứ, có ổn định hay không, và điểm số tạo ra có diễn giải được hay không (AERA, APA, & NCME, 2014; Boateng et al., 2018; Clark & Watson, 1995).
Vì thế, không phải cứ có vài câu hỏi là thành bài test. Theo APA Dictionary of Psychology, một standardized test là công cụ đánh giá mà độ tin cậy và độ giá trị đã được xác lập bằng điều tra và phân tích thực nghiệm kỹ lưỡng; còn Standards for Educational and Psychological Testing nhấn mạnh rằng điều cần được kiểm định không phải “cái test nói chung”, mà là các diễn giải điểm số cho mục đích sử dụng cụ thể (American Psychological Association, 2023; AERA et al., 2014). Nói đơn giản: câu hỏi có thể hay, nhưng nếu chưa qua chuẩn hoá và kiểm định, nó mới chỉ là bộ câu hỏi, chưa phải bài test.
Khi người làm test bỏ qua các bước như xác định cấu trúc nhân tố, phân tích mục, kiểm tra thiên lệch nhóm, chuẩn hoá cách làm và chuẩn hoá mẫu, hậu quả không chỉ là “thiếu chuẩn” về học thuật. Nó còn dẫn tới điểm số méo nghĩa, gán nhãn sai, can thiệp sai, và vi phạm đạo đức khi người tham gia không được giải thích đầy đủ hoặc khi dùng công cụ chưa có bằng chứng phù hợp cho nhóm dân số đang đo (APA, 2010; ITC, 2017; White et al., 2022).
Thang đo tâm lý là gì
Trong đo lường, Stevens (1946) phân biệt bốn mức đo cổ điển: danh nghĩa dùng số như nhãn; thứ tự cho biết hơn kém; khoảng cho phép so sánh chênh lệch nhưng không có số 0 tuyệt đối; tỉ lệ có số 0 tuyệt đối nên diễn giải “gấp đôi” có ý nghĩa. Điểm quan trọng là: đây là mức đo của dữ liệu, không phải tên của các kiểu bảng hỏi. Stevens còn lưu ý rằng nhiều thang đo tâm lý trong thực hành có bản chất gần với thứ tự, dù người dùng hay xử lý như dữ liệu khoảng.
Còn các tên như Likert, Guttman, hay semantic differential là chiến lược xây mục và đáp án. Likert (1932) mô tả cách gán giá trị số cho các lựa chọn phản hồi có trật tự, thường 5 mức; sau đó cộng hoặc lấy trung bình điểm qua nhiều mục để ước lượng thái độ. Guttman thì đi theo logic lũy tích/hệ bậc: nếu đồng ý với mệnh đề “mạnh” hơn, người làm test cũng có xu hướng đồng ý với mệnh đề “nhẹ” hơn. Semantic differential của Osgood, Suci, và Tannenbaum (1957) lại dùng các cặp tính từ đối cực như tốt–xấu, mạnh–yếu, nhanh–chậm để đặt khái niệm vào không gian nghĩa. Nói gọn: bốn mức đo của Stevens trả lời câu hỏi “dữ liệu này cho phép làm toán gì”, còn Likert/Guttman/semantic differential trả lời “ta hỏi và chấm theo cách nào”.
Một thang đo tâm lý tốt luôn đứng trên vài khái niệm nền. Biến là cái ta muốn đo; trong tâm lý học, nhiều biến là biến tiềm ẩn nên phải suy ra từ tập mục hỏi. Độ tin cậy là mức nhất quán của điểm số; nó có thể được xem qua nội tại giữa các mục, độ ổn định theo thời gian, hay sự nhất quán giữa các lần chấm. Độ giá trị/hiệu lực không phải “test tốt hay xấu” theo kiểu chung chung, mà là mức độ bằng chứng và lý thuyết ủng hộ cách diễn giải điểm số cho mục đích cụ thể. Cấu trúc nhân tố cho biết các mục quy tụ thành mấy chiều và có đúng với lý thuyết không (AERA et al., 2014; Revelle & Condon, 2019; DeVellis, 2017).
Vì sao vài câu hỏi chưa thành bài test
Lý do đầu tiên là thiếu mục tiêu đo lường rõ ràng. Clark và Watson (1995) nói rất thẳng: muốn phát triển thang đo có giá trị, phải bắt đầu từ việc khái niệm hoá thật rõ biến mục tiêu; nếu biến còn mơ hồ, câu hỏi sẽ đo lẫn lộn nhiều thứ. Một bộ 8 câu hỏi về “sức khoẻ tinh thần” mà câu thì hỏi buồn bã, câu hỏi kỷ luật bản thân, câu hỏi chất lượng ngủ, câu hỏi tự tin xã hội có thể nghe hợp lý, nhưng về đo lường nó đang trộn nhiều cấu trúc khác nhau. Khi đó tổng điểm không còn nghĩa rõ nữa.
Lý do thứ hai là thiếu chuẩn hoá. Một bài test phải có hướng dẫn đủ cụ thể: ai được làm, làm trong điều kiện nào, chấm ra sao, diễn giải ra sao, và nếu cần thì so với mẫu chuẩn nào. Standards yêu cầu nhà phát triển phải nói rõ thủ tục diễn giải điểm và, khi phù hợp, phải nêu mẫu chuẩn hoá/norming sample hoặc tiêu chuẩn đối chiếu; NCBI cũng tóm lược rằng một psychometric test đầy đủ cần có độ tin cậy, độ giá trị, cách admin chuẩn và dữ liệu chuẩn liên quan (AERA et al., 2014; White et al., 2022). Nếu thiếu phần này, hai người làm cùng một “test” chưa chắc được so sánh công bằng.
Lý do thứ ba là độ tin cậy không tự nhiên mà có. Cronbach (1951) xây dựng hệ số alpha để ước lượng tính nhất quán nội tại; nhưng sau này Revelle và Condon (2019) cùng nhiều tác giả khác nhấn mạnh rằng alpha chỉ là một chỉ số, không phải giấy chứng nhận “test tốt”. Nếu mục hỏi chồng lặp, quá giống nhau, alpha có thể cao mà thang đo vẫn hẹp, nghèo nội dung, hoặc đa chiều ngầm. Bởi vậy, ngoài alpha cần xem thêm omega, test–retest, thậm chí cách điểm số vận hành theo nhiều nguồn sai số khác nhau.
Lý do thứ tư là độ giá trị không thể tự tuyên bố. Standards nêu rõ bằng chứng giá trị có thể đến từ nội dung test, cấu trúc bên trong, và quan hệ với biến bên ngoài; Cronbach và Meehl (1955) thì đặt nền cho ý tưởng rằng muốn nói một test đo “một cấu trúc tâm lý”, phải có mạng lưới bằng chứng lý thuyết và thực nghiệm, chứ không chỉ có cảm giác “câu hỏi nghe đúng”. Một bảng câu hỏi “tự chế” chưa qua phản biện chuyên gia, chưa qua EFA/CFA, chưa chứng minh hội tụ với công cụ cùng cấu trúc và phân biệt với cấu trúc khác, thì chưa đủ cơ sở gọi là test.
Lý do thứ năm là mục hỏi phải biết “làm việc”. DeVellis (2017) chỉ ra rằng cần xem corrected item–total correlation để biết một mục có ăn khớp với toàn thang hay không; mục có tương quan thấp thường là mục kém. Likert (1932) cũng đã dùng item analysis và internal consistency để lựa các câu phân biệt tốt giữa nhóm điểm cao và nhóm điểm thấp. Nếu mục nào ai cũng trả lời giống nhau, hoặc đáp ứng ngược logic, nó không giúp đo — nó chỉ làm nhiễu.
Lý do thứ sáu là điểm số còn phải đủ nhạy và đủ công bằng. Nếu phần lớn người làm đều dồn ở đáy hoặc trần điểm, công cụ sẽ kém khả năng phân loại; nếu mục hoạt động khác nhau giữa các nhóm dù có cùng mức đặc tính cần đo, đó là dấu hiệu bias/DIF. Standards mô tả DIF là hiện tượng các nhóm có mức năng lực tương đương nhưng đáp án hệ thống khác nhau ở một mục; khi đó nhà phát triển phải xem có yếu tố không liên quan đến cấu trúc cần đo đang chen vào hay không. Đây là chỗ mà ngôn ngữ, bối cảnh văn hoá, định kiến khuôn mẫu, cách trình bày, và tải ngôn ngữ đều có thể làm hỏng test.
Lý do cuối cùng là đạo đức và pháp lý. APA yêu cầu khi phát triển test phải dùng thủ tục psychometric phù hợp, chú ý chuẩn hoá, xác thực, giảm bias; khi dùng công cụ chưa có bằng chứng tin cậy/giá trị cho nhóm dân số đang đo, phải nói rõ điểm mạnh và giới hạn. Người tham gia cũng cần được giải thích mục đích, giới hạn bảo mật, và quyền được hỏi lại. Với công cụ có bản quyền, việc sao chép nguyên văn, sửa mục, hoặc phát tán tài liệu test còn có thể vi phạm quyền xuất bản hoặc điều khoản sử dụng của nhà phát hành (APA, 2010; APA, n.d.; Pearson, n.d.).
Quy trình chuẩn xây dựng và kiểm định
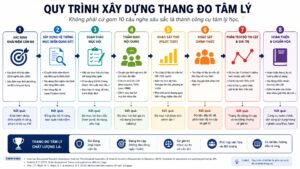
Quy trình chuẩn, nếu rút gọn cho bối cảnh người trưởng thành nói tiếng Việt, thường đi theo logic sau. Trước hết, phải xác định rõ cấu trúc cần đo: tên biến là gì, ranh giới ở đâu, khác gì với biến gần nó. Sau đó tạo item pool rộng hơn cần thiết bằng cả hướng suy diễn từ lý thuyết/literature và hướng quy nạp từ phỏng vấn, nhóm tập trung, quan sát thực tế. Boateng et al. (2018) gọi đây là giai đoạn phát triển mục; Clark và Watson (1995) khuyên item pool ban đầu nên “overinclusive”, còn DeVellis (2017) nói ngắn gọn: ban đầu thường nhiều mục hơn mức cuối cùng là điều tốt.
Tiếp theo là thẩm định chuyên gia và thử thăm dò. Chuyên gia kiểm tra mức phù hợp nội dung, độ rõ nghĩa, độ đại diện miền nội dung; người tham gia thật giúp phát hiện câu khó hiểu, từ mơ hồ, hoặc đáp án không khớp trải nghiệm. Sau đó mới đi vào phân tích mục: xem mức phân biệt, corrected item–total correlation, phân bố đáp án, độ khó/endorsement, và những mục nào đo lệch khỏi mục tiêu. Với thang tự báo cáo, “độ khó” không phải đúng-sai theo nghĩa hẹp, mà là mức đặc tính mà ở đó người trả lời bắt đầu có xu hướng endorse mục đó; DeVellis (2017) giải thích khái niệm này từ cả góc nhìn IRT.
Sau bước mục là phân tích cấu trúc. EFA giúp dò xem bao nhiêu nhân tố nằm dưới bộ mục; CFA kiểm xem mô hình lý thuyết có khớp dữ liệu không. DeVellis (2017) nhấn mạnh factor analysis giúp xác định có bao nhiêu latent variables dưới một tập mục và nhận diện mục hoạt động kém; Clark và Watson (1995) xem factor analysis là chìa khoá để bảo đảm tính đơn chiều và độ phân biệt giữa các thang con. Sau đó, mới kiểm độ tin cậy bằng alpha, omega, test–retest; và kiểm độ giá trị bằng nội dung, cấu trúc, hội tụ/phân biệt, hay quan hệ với biến bên ngoài.
Bước cuối là chuẩn hoá và thích nghi bối cảnh dùng. Nếu dịch sang tiếng Việt, ITC (2017) khuyến nghị quy trình dịch–ngược dịch–đối chiếu ý nghĩa–kiểm tra thực nghiệm; còn Standards và NCBI nhấn mạnh rằng mẫu chuẩn hoặc ít nhất dữ liệu kiểm định phải phù hợp ngôn ngữ, văn hoá, tuổi, và dân số đích. Thiếu bước này, cùng một bộ câu hỏi có thể cho ra điểm số “đúng hình thức nhưng sai nghĩa”.
Đánh giá tính cách – Personality Inventory (EPI)
Bảng tiêu chí cốt lõi
Bảng dưới đây là bản tóm lược các bước và tiêu chí nên có khi xây thang đo tâm lý cho người trưởng thành nói tiếng Việt, tổng hợp từ Boateng et al. (2018), DeVellis (2017), Clark và Watson (1995), Revelle và Condon (2019), Standards (2014), và White et al. (2022).
| Giai đoạn | Câu hỏi chính | Kiểm định/chỉ số thường dùng | Dấu hiệu đạt |
|---|---|---|---|
| Xác định cấu trúc | Mình đang đo đúng biến nào? | Định nghĩa lý thuyết, phân biệt với biến gần kề | Biến có ranh giới rõ |
| Tạo mục | Mục có phủ đủ nội dung không? | Review lý thuyết, phỏng vấn, focus group, expert review | Item pool rộng, rõ, không mơ hồ |
| Thử thăm dò | Người làm có hiểu giống mình không? | Pilot, cognitive interview | Ít câu hiểu sai, ít bỏ sót |
| Phân tích mục | Mục nào đóng góp tốt? | Corrected item–total, phân biệt, phân bố đáp án, endorsement/độ khó | Loại mục yếu, mục ngược logic |
| Cấu trúc nhân tố | Bộ mục có mấy chiều? | EFA, CFA | Mô hình phù hợp lý thuyết và dữ liệu |
| Độ tin cậy | Điểm có ổn định, nhất quán không? | Alpha, omega, test–retest | Đủ nhất quán và ổn định |
| Độ giá trị | Điểm có diễn giải được không? | Nội dung, cấu trúc, quan hệ với biến ngoài | Có bằng chứng cho mục đích dùng |
| Chuẩn hoá | Điểm này có so sánh được không? | Mẫu chuẩn, hướng dẫn admin/chấm, tài liệu diễn giải | Dùng nhất quán, diễn giải được |
| Công bằng và đạo đức | Công cụ có thiên lệch hay gây hại không? | DIF, sensitivity review, consent, bảo mật | Giảm bias, minh bạch giới hạn |
Ví dụ minh họa
Một ví dụ tốt là PHQ-9. Bản gốc của Kroenke, Spitzer, và Williams (2001) cho thấy công cụ 9 mục này vừa hỗ trợ chẩn đoán tạm thời, vừa đo mức độ nặng của triệu chứng trầm cảm; các ngưỡng điểm 5, 10, 15, 20 tương ứng với các mức độ nặng tăng dần. Quan trọng hơn, PHQ-9 không nổi tiếng vì “chỉ có 9 câu”, mà vì có quy tắc chấm rõ, ngưỡng diễn giải rõ, nghiên cứu độ tin cậy/giá trị rõ. Trong bối cảnh Việt Nam, một nghiên cứu năm 2023 ở chăm sóc sức khỏe ban đầu kết luận bản tiếng Việt của PHQ-9 là công cụ valid and reliable cho sàng lọc MDD; báo cáo này cũng cho thấy alpha chấp nhận được và bằng chứng hiệu lực đồng quy với các thang trầm cảm khác. Đây là ví dụ của một thang đo đi từ lý thuyết, mục hỏi, chấm điểm đến kiểm định thực nghiệm tương đối rõ ràng.
Ngược lại, hãy tưởng tượng một “test trầm cảm online” gồm 7 câu tự chế như: “Bạn hay buồn không?”, “Bạn có stress không?”, “Bạn thấy mình thất bại không?”, “Bạn có lười không?”, rồi cộng điểm để kết luận “nhẹ/vừa/nặng”. Ví dụ này thất bại ở gần như mọi tầng: cấu trúc mục tiêu mơ hồ, trộn lo âu–trầm cảm–động lực–tự đánh giá; không có phản biện nội dung; chưa qua phân tích mục; chưa biết một hay nhiều nhân tố; chưa có alpha/omega/test–retest; chưa đối chiếu với công cụ chuẩn; chưa có chuẩn hoá ngôn ngữ, mẫu, hoặc điểm cắt; lại còn có nguy cơ dùng từ gây phán xét như “lười”. Dưới góc đo lường, nó chỉ là bộ câu hỏi cảm tính. Dưới góc đạo đức, nó có thể dẫn tới gán nhãn sai và khuyến nghị sai.
Sơ đồ quy trình
Sơ đồ dưới đây rút từ logic phát triển thang đo của Boateng et al. (2018), DeVellis (2017), Clark và Watson (1995), cùng các chuẩn đo lường của AERA/APA/NCME.
Nguồn trích dẫn APA và giới hạn
Các nguồn học thuật/chính thức được dùng trực tiếp trong báo cáo gồm:
- American Educational Research Association, American Psychological Association, & National Council on Measurement in Education. (2014). Standards for educational and psychological testing. AERA.
- American Psychological Association. (2023). Standardized test. APA Dictionary of Psychology.
- American Psychological Association. (2010). Ethical principles of psychologists and code of conduct (effective June 2003, amended 2010).
- Boateng, G. O., Neilands, T. B., Frongillo, E. A., Melgar-Quiñonez, H. R., & Young, S. L. (2018). Best practices for developing and validating scales for health, social, and behavioral research: A primer. Frontiers in Public Health, 6, 149.
- Clark, L. A., & Watson, D. (1995). Constructing validity: Basic issues in objective scale development. Psychological Assessment, 7(3), 309–319.
- Cronbach, L. J. (1951). Coefficient alpha and the internal structure of tests. Psychometrika, 16, 297–334.
- Cronbach, L. J., & Meehl, P. E. (1955). Construct validity in psychological tests. Psychological Bulletin, 52(4), 281–302.
- DeVellis, R. F. (2017). Scale development: Theory and applications (4th ed.). SAGE.
- International Test Commission. (2017). The ITC guidelines for translating and adapting tests (2nd ed.).
- Kroenke, K., Spitzer, R. L., & Williams, J. B. W. (2001). The PHQ-9: Validity of a brief depression severity measure. Journal of General Internal Medicine, 16(9), 606–613.
- Likert, R. (1932). A technique for the measurement of attitudes. Archives of Psychology, 140, 1–55.
- Osgood, C. E., Suci, G. J., & Tannenbaum, P. H. (1957). The measurement of meaning. University of Illinois Press.
- Phi, H. N. Y., và cs. (2023). Psychometric properties of Vietnamese versions of the Quick Inventory of Depressive Symptomatology and the Patient Health Questionnaire-9 in primary healthcare settings.
- Revelle, W., & Condon, D. M. (2019). Reliability from α to ω: A tutorial.
- Stevens, S. S. (1946). On the theory of scales of measurement. Science, 103(2684), 677–680.
- White, R. F., Braun, J. M., Kopylev, L., et al. (2022). Part 1: Principles for evaluating psychometric tests. In NIEHS report on evaluating features and application of neurodevelopmental tests in epidemiological studies.
Giới hạn nhỏ của báo cáo này là: tôi tìm được bằng chứng mạnh về bản gốc và bản tiếng Việt đã được kiểm định của một số công cụ như PHQ-9, nhưng chưa xác nhận được một bộ chuẩn quốc gia mở truy cập cho mọi nhóm người trưởng thành Việt Nam. Vì vậy, ví dụ “thang đo tốt” ở đây nên hiểu là công cụ có cấu trúc lý thuyết, quy trình chấm, bằng chứng tin cậy/giá trị và thích nghi ngôn ngữ rõ ràng, chứ không khẳng định đã có chuẩn dân số toàn quốc cho mọi mục đích sử dụng.